PIB de la Eurozona desestacionalizado
Datos
- \(\texttt{GDP_EZ19}\) (\(Y_t\)):
- serie temporal del PIB trimestral de la Eurozona (19 países) en miles de millones de dólares, desestacionalizada. La muestra abarca desde el primer trimestre de 1995 hasta el primero de 2024.
Modelos ARIMA (con y sin intervención) estimados usando la muestra hasta el cuarto trimestre de 2019. Las previsiones corresponden al periodo posterior a 2019 (posterior a la aparición de la pandemia por COVID).
- Ficheros:
- Versión del ejercicio en pdf; html.
- Datos: GDP_Eurozona_desestacionalizado.gdt
- Guión de gretl: Examen-GDP_EuroZonaDesestacionalizado.inp
logs GDP_EZ19
Modelos
Modelo 1
smpl 1995:1 2019:4
arima 2 1 0 ; l_GDP_EZ19
modtest --normality --quiet
modtest --arch 4 --quiet
modtest --autocorr 36 --quiet
Function evaluations: 22
Evaluations of gradient: 7
Model 1: ARIMA, using observations 1995:2-2019:4 (T = 99)
Estimated using AS 197 (exact ML)
Dependent variable: (1-L) l_GDP_EZ19
Standard errors based on Hessian
coefficient std. error z p-value
-------------------------------------------------------
const 0.00381874 0.00114566 3.333 0.0009 ***
phi_1 0.552936 0.0998859 5.536 3.10e-08 ***
phi_2 0.0497438 0.0996677 0.4991 0.6177
Mean dependent var 0.003845 S.D. dependent var 0.005721
Mean of innovations -0.000016 S.D. of innovations 0.004603
R-squared 0.997936 Adjusted R-squared 0.997914
Log-likelihood 392.0319 Akaike criterion -776.0639
Schwarz criterion -765.6834 Hannan-Quinn -771.8639
Real Imaginary Modulus Frequency
-----------------------------------------------------------
AR
Root 1 1.5831 0.0000 1.5831 0.0000
Root 2 -12.6988 0.0000 12.6988 0.5000
-----------------------------------------------------------
Test for null hypothesis of normal distribution:
Chi-square(2) = 49.359 with p-value 0.00000
Test for ARCH of order 4
Test statistic: TR^2 = 45.483132,
with p-value = P(Chi-square(4) > 45.483132) = 0.000000
Test for autocorrelation up to order 36
Ljung-Box Q' = 19.1556,
with p-value = P(Chi-square(34) > 19.1556) = 0.9810
Modelo 2
Modelo de intervención con una raíz unitaria. Las variables explicativas son de tipo escalón; toman el valor 1 desde el trimestre indicado en el nombre en adelante (en stepAAT, AA indica el
año y T el trimestre; por ejemplo, step082 toma el valor 0 hasta el primer trimestre de 2008 y 1 en el segundo trimestre y siguientes). Dichas variables corresponden a los periodos 2008Q2–2009Q2 (para La Gran Recesión) y 2011Q2–2013Q1 (para La Crisis de Deuda Soberana).
smpl 1995:1 2019:4
arima 2 1 0 ; l_GDP_EZ19 const STEPS
modtest --normality --quiet
modtest --arch 4 --quiet
modtest --autocorr 36 --quiet
Function evaluations: 269
Evaluations of gradient: 127
Model 2: ARMAX, using observations 1995:2-2019:4 (T = 99)
Estimated using AS 197 (exact ML)
Dependent variable: (1-L) l_GDP_EZ19
Standard errors based on Hessian
coefficient std. error z p-value
---------------------------------------------------------
const 0.00522225 0.000584760 8.931 4.24e-19 ***
phi_1 0.269237 0.0974100 2.764 0.0057 ***
phi_2 0.278282 0.0983383 2.830 0.0047 ***
step082 -0.00869573 0.00258841 -3.359 0.0008 ***
step083 -0.00995842 0.00266351 -3.739 0.0002 ***
step084 -0.0232487 0.00278175 -8.358 6.40e-17 ***
step091 -0.0361984 0.00266528 -13.58 5.16e-42 ***
step092 -0.00514075 0.00259049 -1.984 0.0472 **
step112 -0.00627135 0.00261486 -2.398 0.0165 **
step113 -0.00503973 0.00270948 -1.860 0.0629 *
step114 -0.00992046 0.00285619 -3.473 0.0005 ***
step121 -0.00810677 0.00288147 -2.813 0.0049 ***
step122 -0.00775415 0.00287817 -2.694 0.0071 ***
step123 -0.00638413 0.00284855 -2.241 0.0250 **
step124 -0.00982856 0.00269473 -3.647 0.0003 ***
step131 -0.00829478 0.00260583 -3.183 0.0015 ***
Mean dependent var 0.003845 S.D. dependent var 0.005721
Mean of innovations 1.69e-06 S.D. of innovations 0.002587
R-squared 0.999340 Adjusted R-squared 0.999230
Log-likelihood 449.1317 Akaike criterion -864.2635
Schwarz criterion -820.1464 Hannan-Quinn -846.4136
Real Imaginary Modulus Frequency
-----------------------------------------------------------
AR
Root 1 1.4726 0.0000 1.4726 0.0000
Root 2 -2.4401 0.0000 2.4401 0.5000
-----------------------------------------------------------
Test for null hypothesis of normal distribution:
Chi-square(2) = 3.199 with p-value 0.20203
Test for ARCH of order 4
Test statistic: TR^2 = 1.747684,
with p-value = P(Chi-square(4) > 1.747684) = 0.782039
Test for autocorrelation up to order 36
Ljung-Box Q' = 25.4791,
with p-value = P(Chi-square(34) > 25.4791) = 0.8536
Previsiones del modelo 2
fcast 2005:1 2023:3 --plot="prediccion.png"
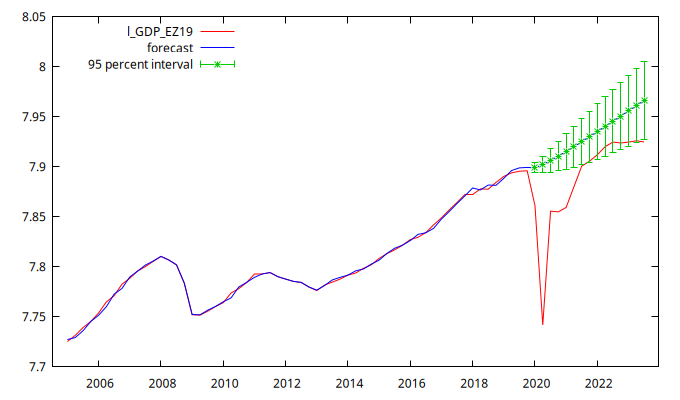
Figura 1: Resultados de previsión extramuestral (desde el primer trimestre de 2020 hasta el primero de 2024) calculados a partir del modelo ARMAX. La figura muestra los valores observados, los valores ajustados, las previsiones y los correspondientes intervalos de confianza al 95%.
Preguntas
Pregunta 1
(2 puntos) Comente exhaustivamente los resultados de estimación y diagnosis de los modelos 1 y 2. Indique en cada caso si el coeficiente de determinación \(R^2\) puede interpretarse como el porcentaje de varianza de la variable endógena que explica el modelo. ¿Muestran los modelos algún indicio de sobrediferenciación o infradiferenciación?
Pregunta 2
(2 puntos) Compare los modelos 1 (ARIMA) y 2 (ARMAX). ¿Cuál de los dos modelos:
- ajusta mejor la muestra?
- cabe esperar que esté mejor especificado?
- muestra mejores estadísticos residuales?
Interprete los coeficientes de las variables exógenas step082 y step083 en el modelo 2.
¿Cuál es su interpretación económica considerando cada coeficiente por separado?
¿Cuál es la interpretación económica de la suma de ambos coeficientes?
Pregunta 3
(2 puntos) Compare las previsiones extramuestrales de la figura 1 con los correspondientes valores observados.
- Dado el horizonte de previsión considerado, la divergencia entre ambas series… ¿implica que el modelo es estadísticamente inadecuado y por eso predice mal?
- ¿Cómo interpretaría la diferencia entre ambas sendas (la prevista y la observada) en el período de la pandemia: enero de 2020 hasta diciembre de 2021?
- ¿Cómo pueden haber afectado los eventos bélicos recientes (invasión de Ucrania en febrero de 2022 e invasión israelí de la franja de Gaza en octubre de 2023) a la evolución real del PIB en comparación con la senda prevista?
- ¿Está convergiendo el PIB a la senda de crecimiento pre-pandemia?
Pregunta 4
(1.5 pts. — cada apartado correcto \(0.15\) pts. Cada apartado incorrecto \(-0.15\) pts.)
Indique explícitamente en cada caso si la expresión es correcta o no (si no lo es, indique el motivo).
Redondeando a tres decimales, el modelo 1 (ARIMA) puede escribirse matemáticamente como (preste atención al orden de las transformaciones, el signo de los parámetros, la coherencia de la expresión, etc.):
- \(\nabla\big(\ln GPD_t -0,004 \big)= \frac{1}{1 -0,553 \, B -0,050\, B^2} \hat{a}_t\)
- \(\nabla \ln GPD_t -0,004 = \frac{1}{1 -0,553 \, B -0,050\, B^2} \hat{a}_t\)
- \(\ln GPD_t - 0,004= \nabla(1 \, - \, 0,553 \, B \, - \, 0,050\, B^2) \, \hat{a}_t\)
- \( \nabla\ln GPD_t - \nabla \, 0,004 = \frac{1}{1 \, - \, 0,553 \, B \, - \, 0,050\, B^2} \hat{a}_t\)
- \( (1 \, + \, 0,553 \, B \, + \, 0,050\, B^2) \nabla \, (\ln GPD_t + 0,004) = \hat{a}_t\)
- \( (1 \, - \, 0,553 \, B \, - \, 0,050\, B^2) (\nabla\ln GPD_t - 0,004) = \hat{a}_t\)
- \( (1 \, - \, 0,553 \, B \, - \, 0,050\, B^2) \nabla\ln GPD_t = 0,0015 + \hat{a}_t\)
- \( \frac{1}{\nabla(1 \, - \, 0,553 \, B \, - \, 0,050\, B^2)}(\ln GPD_t + 0,004) = \hat{a}_t\)
- \( \frac{1}{1 \, - \, 0,553 \, B \, - \, 0,050\, B^2}(\ln GPD_t - 0,004) = \nabla \hat{a}_t\)
- \( \nabla \ln \, GPD_t - 0,004 = \frac{1}{1 \, - \, 0,553 \, B \, - \, 0,050\, B^2} + \hat{a}_t\)
donde \(0,00381874\times(1-0,552936-0,0497438) \approx 0,0015\)
Grupo de preguntas 5
Para cada afirmación: diga si es verdadera o falsa e incluya una breve explicación.
(0.25 pts. — por cada apartado correctamente justificado)
Pregunta 5.1
El coeficiente de determinación (\( R^2 \)) del modelo 1 (ARIMA) indica que éste consigue captar el 99,79% de la varianza de la variable endógena.
Pregunta 5.2
La desviación típica de los residuos del modelo 2 (ARIMAX) indica que éste ajusta mejor los valores de la variable endógena que el modelo 1 (ARIMA).
Pregunta 5.3
El valor del criterio de Schwarz correspondiente al modelo 2 (ARIMAX) indica este éste podría estar peor especificado que el modelo 1 (ARIMA).
Pregunta 5.4
El valor del criterio de Akaike correspondiente al modelo 2 (ARIMAX) indica éste podría predecir peor que el modelo 1 (ARIMA).
Pregunta 5.5
El módulo de las raíces AR del modelo 1 (ARIMA) para \(\nabla \ln GPD_t\) indican que este podría ser no estacionario.
Pregunta 5.6
El valor de las raíces AR del modelo 1 (ARIMA) indican que éste podría ser no invertible.
Pregunta 5.7
En el modelo 2 (ARIMAX), el coeficiente de la variable step082 es significativo e indica que en el segundo trimestre de 2008 se produjo un descenso transitorio del nivel de PIB en la Eurozona de magnitud aproximadamente igual al 0,87% de PIB de ese trimestre.
Pregunta 5.8
En el modelo 2 (ARIMAX), el coeficiente de la variable step082 es significativo e indica que a partir del segundo trimestre de 2008 se produjo un descenso permanente del nivel de PIB en la Eurozona en una magnitud aproximadamente igual al 0,87% de PIB de ese trimestre.
Pregunta 5.9
El modelo 2 (ARIMAX) implica que: (a) en 2008 y 2011 se produjeron eventos exógenos que redujeron significativamente el PIB de la Eurozona, por debajo de los niveles que se hubiese esperado alcanzar en ausencia de estos eventos y que (b) tras el final de estos eventos, la senda del PIB ha recuperado los mismos niveles que hubiera tenido si dichos eventos no hubieran acaecido.
Pregunta 5.10
El modelo 2 (ARIMAX) indica que: (a) en 2008 y 2011 se produjeron eventos exógenos que redujeron significativamente el PIB de la Eurozona, por debajo de los niveles que se hubiese esperado alcanzar en ausencia de estos eventos y que (b) tras el final de estos eventos, el PIB ha resultado ser siempre inferior a los niveles que hubiera tenido si dichos eventos no hubieran acaecido.
Respuestas
Respuesta 1
En el modelo 1 (ARIMA(2,1,0) del logaritmo del PIB), el coeficiente phi_2 no es estadísticamente significativo. En cuanto a los test de los residuos, se rechazan contundentemente las hipótesis nulas de normalidad y ausencia de efectos ARCH, aunque no se rechaza la hipótesis nula de ausencia de autocorrelación a los niveles habituales de significación.
En el modelo 2 (ARIMAX(2,1,0) del logaritmo del PIB) todos los coeficientes son estadísticamente significativos como mínimo al 5% (a excepción del correspondiente a step113 que es significativo al 10% peor no al 5%, dado que su p-valor es del 6,3%). En cuanto a los test de los residuos, no se rechaza ninguna de las tres hipótesis nulas (citadas en el párrafo anterior) a los niveles habituales de significación.
Ambos modelos ajustan una serie temporal no estacionaria (véase cómo la serie \(\texttt{l_GDP_EZ19}\) deambula en la figura 1). Consecuentemente el coeficiente de determinación \(R^2\) resulta ser muy elevado (algo que no debe ser interpretado de ningún modo, pues es lo que cabe esperar en tales circunstancias incluso en ajustes con modelos mediocres). Pero incluso si estos modelos ajustarán una serie temporal estacionaria, no debería interpretarse el \(R^2\) como el porcentaje de la varianza muestral de la variable endógena que es capaz de ser replicado por el modelo; dicha interpretación solo cabe en modelos de regresión que incluyen término constante y que son estimados por MCO.
En cuanto a la sobrediferenciación o infradiferenciación: en ambos modelos las raíces de los polinomios AR están fuera del círculo de radio unidad, por lo que la diferencia de los datos, (1-L), parece suficiente para inducir la estacionariedad (es decir, no hay indicios de infradiferenciación). Por otra parte, dado que dichos modelos no incorporan ningún polinomio MA, con los resultados de estimación disponibles no es posible anticipar si al incluir un polinomio MA, éste presentaría raíces de modulo 1 (es decir, con los datos de estimación disponibles no podemos ver si hay indicios de sobrediferenciación). No obstante, viendo el perfil de la serie temporal entre los años 2005 y final de 2019 (figura 1), parece claro que la modelización de la serie requiere una diferencia ordinaria (que es lo que incorporan ambos modelos), por lo que no cabe esperar que pueda haber sobrediferenciación por tomar una única diferencia regular.
Respuesta 2
El modelo 2 parece que se ajusta mejor a la muestra, dada la desviación típica de los errores de ajuste (D.T. innovaciones).
Uno de los parámetros del modelo 1 no es estadísticamente significativo a los niveles \(\alpha\) habituales. Pese a ello, dado que el criterio de Schwarz penaliza con mayor severidad el número de parámetros (y que el segundo modelo incluye 13 parámetros más que el primero), el criterio de información bayesiano (BIC o criterio de Schwarz) del primer modelo resulta más favorable que en el segundo. Sin embargo, los otros dos criterios de información indican un mejor desempeño para el modelo 2 (cuyos parámetros son todos significativos).
Los contrastes de los residuos del modelo 2 son mejores que los del modelo 1, salvo en el caso de la autocorrelación; donde ambos modelos presentan conclusiones similares (en ambos claramente NO se rechaza la ausencia de autocorrelación, aunque el p-valor en el primer modelo sea algo mayor).
El coeficiente de la variable exógena step082 indica que en el segundo trimestre de 2008 se produjo una reducción del PIB en la Eurozona de un 0,87% aproximadamente. Análogamente, el coeficiente de la variable exógena step083 indica que en el tercer trimestre de 2008 se produjo una reducción del PIB en la Eurozona de un 1,00% aproximadamente. Por lo tanto, si sumamos ambos efectos, el PIB de la Eurozona experimenta una reducción acumulada de aproximadamente un 1.87% entre el segundo y tercer trimestres de 2008.
Respuesta 3
La figura 1 se puede entender como un análisis contrafactual: permite comparar la senda observada del PIB de la Eurozona con una senda de previsiones calculada con los datos hasta el cuarto trimestre de 2019 (es decir, con los datos anteriores al confinamiento). Esta senda de previsiones se puede interpretar como una estimación de la evolución del PIB en ausencia de la pandemia y los eventos bélicos posteriores.
Como puede verse, las previsiones superan siempre los valores observados, de forma que:
- Entre enero de 2020 hasta diciembre de 2021, el PIB observado está muy por debajo del previsto, quedando incluso fuera del intervalo de confianza del 95%. La distancia entre ambas sendas puede interpretarse como una estimación de la pérdida de riqueza económica imputable a la pandemia y el consecuente confinamiento.
- A finales de 2021 y principios de 2022 el PIB estaba aproximándose a la senda prevista, pero en 2022 inició un movimiento divergente, posiblemente debido a la invasión rusa de Ucrania. La invasión israelí de la franja de Gaza, en octubre de 2023, posiblemente contribuyó al mantenimiento de esta divergencia.
El modelo predice mal los valores desde el primer trimestre de 2020; pero debemos atribuirlo a los sucesos exógenos (y por tanto no previsibles para el modelo) correspondientes a la pandemia y los eventos bélicos posteriores. Por tanto, el mal rendimiento predictivo del modelo no tiene que ver con su calidad estadística.
Respuesta 4
- INCORRECTA (el operador diferencia tan solo debe actuar sobre \(\ln GPD_t\), ya que la constante \(0.004\) es la media de \(\nabla \ln GPD_t\)).
- Correcta (expresión en forma MA(\(\infty\)) de la primera diferencia del logaritmo del PIB menos su media).
- INCORRECTA (ese es un modelo MA(3) no invertible de \(\ln GPD_t\); ni el modelo es MA(3), ni \(\ln GPD_t\) es estacionaria).se corresponde con el modelo ajustado).
- INCORRECTA (es el mismo modelo que en 1.)
- INCORRECTA (el operador diferencia solo debe actuar sobre \(\ln GPD_t\) y los signos de los parámetros \(\phi\) y la constante están cambiados).
- Correcta (es la representación AR de la primera diferencia del logaritmo del PIB menos su media).
- Correcta (es la representación AR(2) de \(\nabla \ln GPD_t\); donde dicho AR(2) tiene un proceso de innovaciones con media \(0,0038\times(1 \, - \, 0,553 \, B \, - \, 0,050\, B^2)\)).
- INCORRECTA (el polinomio AR aparece en el denominador y el operador diferencia también).
- INCORRECTA (el polinomio AR aparece en el denominador de la parte AR; y el operador actúa sobre las innovaciones).
- INCORRECTA (la fracción \(\frac{1}{1 \, - \, 0,553 \, B \, - \, 0,050\, B^2}\) debe multiplicar (no sumar) a las innovaciones).
Respuesta 5.1
FALSO. Esa interpretación solo es correcta si está referida a la varianza muestral de la variable endógena en modelos regresión con un regresor constante y estimados por MCO. Éste no es un modelo de regresión; es un modelo ARIMA estimado por máxima verosimilitud, por lo que no cabe dicha interpretación.
Respuesta 5.2
La afirmación es verdadera. Una menor desviación típica de los residuos (D.T. innovaciones) indica unos errores de ajuste más pequeños cuando los errores tienen media cero; que es aproximadamente el caso ya que en el primer modelo tienen media -0,000016 y en el segundo 1,69e-06. La magnitud de los residuos es \(\sqrt{\sigma^2+\mu^2}\) que en el primer caso arroja un valor de \(0.0046\) y en el segundo de \(0.0026\).
Respuesta 5.3
La afirmación es FALSA ya que el valor del criterio de Schwarz correspondiente al modelo que aparece en el modelo 2 (ARIMAX) es menor, es decir, mejor.
Respuesta 5.4
La afirmación es FALSA, ya que el valor del criterio de Akaike correspondiente al modelo 2 (ARIMAX) es menor, es decir, mejor.
Respuesta 5.5
La afirmación es FALSA. El módulo de las raíces AR del modelo es mayor que 1, lo que indica que el modelo de la primera diferencia del logaritmo del PIB es estacionario (no así el modelo del logaritmo del PIB sin diferenciar).
Respuesta 5.6
La afirmación es FALSA. Un modelo AR siempre es invertible.
Respuesta 5.7
La afirmación es FALSA. Ese coeficiente denota que, a partir del segundo trimestre de 2008, la senda de evolución del PIB experimentó un descenso permanente en su nivel respecto a lo que habría sido el nivel de su evolución de no acaecer la crisis financiera de 2008 (fíjese que ese coeficiente corresponde a una variable de tipo escalón). La magnitud de dicho descenso en el nivel de la senda fue igual al 0,87% del valor del PIB en el segundo trimestre de 2008.
Respuesta 5.8
La afirmación es verdadera. Ese coeficiente denota que se produjo un descenso persistente en el nivel de PIB, ya que afecta a una variable de tipo escalón.
Respuesta 5.9
La afirmación es FALSA. Las variables exógenas indican que, en 2008 y en 2011, el PIB se redujo de manera permanente por debajo de los niveles que para trimestre se hubieran alcanzado en ausencia de dichas crisis.
Lo único que se recupera es la pendiente promedio de la serie, es decir, su ritmo de crecimiento a largo plazo. Sin embargo, el nivel del PIB ya siempre será inferior al que habría alcanzado sin las crisis, dando como resultado una pérdida permanente de renta.
Respuesta 5.10
La afirmación es verdadera. La reducción del PIB experimentada en 2008 y 2011, reflejada en los parámetros de las variables exógenas, indica que el nivel del PIB en cada trimestre será permanentemente inferior al que habría alcanzado en ausencia de las crisis.