Saldo de otros activos/pasivos con respecto al resto del mundo
Los datos
Los datos de este ejercicio corresponden a la serie temporal de la base de datos del Banco de España correspondiente a la cuenta financiera del saldo de otros activos/pasivos con respecto al resto del mundo (todos los sectores). Son datos trimestrales en miles de euros.
Para abrir los datos, debe estar instalada la base de datos del Banco de España: ``Pinchar'' en menú desplegable: Archivo –> Bases de datos y pulsar en el icono Mirar en el Servidor. Buscar en el listado la base de datos
bey pulsar con el ratón dos veces sobre ella.
- Ficheros
- Versiones: pdf; html.
- Datos: Examen-SaldoOtrosActivosPasivosRespectoMundo.gdt
- Guión de gretl: Examen-SaldoOtrosActivosPasivosRespectoMundo.inp
Cuentas Financieras. Metodología SEC2010. Saldo. Otros activos/pasivos. Todos los sectores. Resto del mundo, Miles de Euros
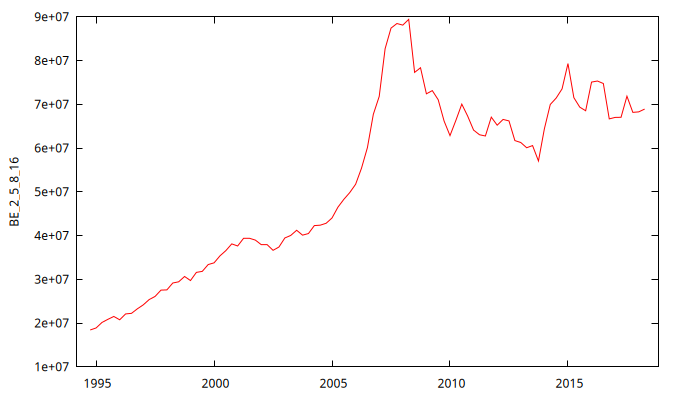
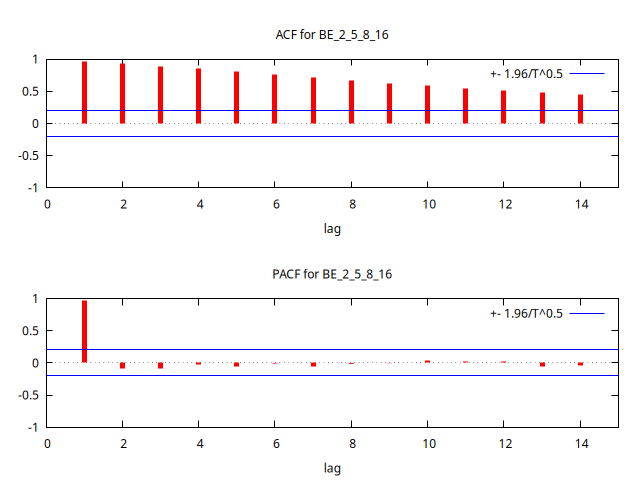
Gráfico de la serie temporal y su correlograma:
gnuplot BE_2_5_8_16 --time-series --with-lines --output="otros.png"
corrgm BE_2_5_8_16 14 --plot="otrosACF-PACF.png"
Estadístico Ljung-Box para los primeros retardos
Autocorrelation function for BE_2_5_8_16
***, **, * indicate significance at the 1%, 5%, 10% levels
using standard error 1/T^0.5
LAG ACF PACF Q-stat. [p-value]
1 0.9679 *** 0.9679 *** 91.8389 [0.000]
2 0.9316 *** -0.0831 177.8299 [0.000]
3 0.8902 *** -0.0947 257.2105 [0.000]
4 0.8483 *** -0.0221 330.0793 [0.000]
5 0.8041 *** -0.0525 396.2819 [0.000]
6 0.7606 *** -0.0096 456.1772 [0.000]
7 0.7150 *** -0.0543 509.7136 [0.000]
8 0.6701 *** -0.0147 557.2739 [0.000]
9 0.6263 *** -0.0046 599.3036 [0.000]
10 0.5865 *** 0.0331 636.5943 [0.000]
Contrastes de raíz unitaria
Contraste Dickey-Fuller aumentado de raíz unitaria
adf 4 BE_2_5_8_16 --nc --test-down=AIC
Augmented Dickey-Fuller test for BE_2_5_8_16 testing down from 4 lags, criterion AIC sample size 92 unit-root null hypothesis: a = 1 test without constant including 2 lags of (1-L)BE_2_5_8_16 model: (1-L)y = (a-1)*y(-1) + ... + e estimated value of (a - 1): 0.00249053 test statistic: tau_nc(1) = 0.413969 asymptotic p-value 0.8025 1st-order autocorrelation coeff. for e: 0.021 lagged differences: F(2, 89) = 3.372 [0.0388]
Contraste KPSS de estacionariedad
kpss 4 BE_2_5_8_16
KPSS test for BE_2_5_8_16
T = 95
Lag truncation parameter = 4
Test statistic = 1.62178
10% 5% 1%
Critical values: 0.350 0.462 0.734
P-value < .01
Datos en primeras diferencias
diff BE_2_5_8_16
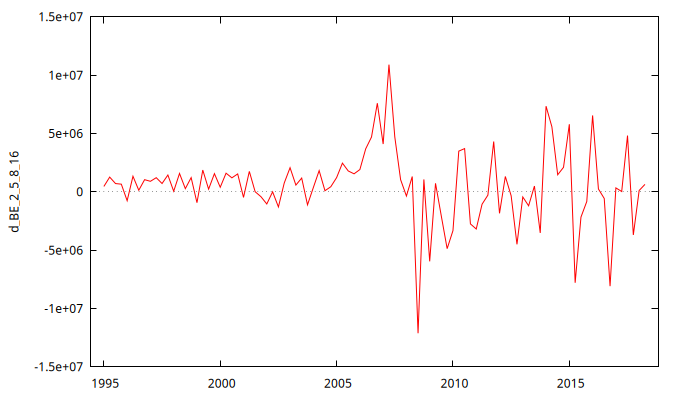
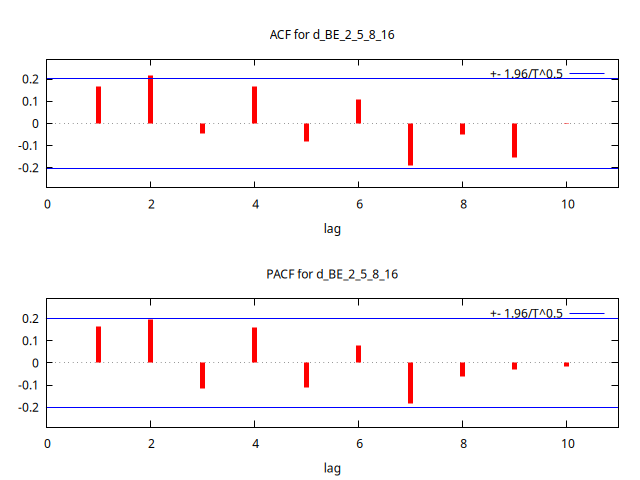
Gráfico de la serie temporal en diferencias y su correlograma:
gnuplot d_BE_2_5_8_16 --time-series --with-lines --output="d_otros.png"
corrgm d_BE_2_5_8_16 10 --plot="d_otrosACF-PACF.png"
Estadístico Ljung-Box para los primeros retardos
Autocorrelation function for d_BE_2_5_8_16
***, **, * indicate significance at the 1%, 5%, 10% levels
using standard error 1/T^0.5
LAG ACF PACF Q-stat. [p-value]
1 0.1651 0.1651 2.6456 [0.104]
2 0.2170 ** 0.1951 * 7.2644 [0.026]
3 -0.0451 -0.1134 7.4658 [0.058]
4 0.1684 0.1608 10.3084 [0.036]
5 -0.0802 -0.1089 10.9612 [0.052]
6 0.1065 0.0768 12.1235 [0.059]
7 -0.1918 * -0.1822 * 15.9406 [0.026]
8 -0.0491 -0.0602 16.1933 [0.040]
9 -0.1519 -0.0304 18.6431 [0.028]
10 -0.0021 -0.0184 18.6435 [0.045]
Contrastes de raíz unitaria
Contraste Dickey-Fuller aumentado de raíz unitaria
adf 4 d_BE_2_5_8_16 --nc --test-down=AIC
Augmented Dickey-Fuller test for d_BE_2_5_8_16 testing down from 4 lags, criterion AIC sample size 92 unit-root null hypothesis: a = 1 test without constant including one lag of (1-L)d_BE_2_5_8_16 model: (1-L)y = (a-1)*y(-1) + ... + e estimated value of (a - 1): -0.641894 test statistic: tau_nc(1) = -4.89044 asymptotic p-value 1.259e-06 1st-order autocorrelation coeff. for e: 0.020
Contraste KPSS de estacionariedad
kpss 4 d_BE_2_5_8_16
KPSS test for d_BE_2_5_8_16
T = 94
Lag truncation parameter = 4
Test statistic = 0.122829
10% 5% 1%
Critical values: 0.350 0.462 0.733
P-value > .10
Primer modelo univariante tentativo
arima 2 1 0 ; BE_2_5_8_16
Function evaluations: 22
Evaluations of gradient: 6
Model 2: ARIMA, using observations 1995:1-2018:2 (T = 94)
Estimated using AS 197 (exact ML)
Dependent variable: (1-L) BE_2_5_8_16
Standard errors based on Hessian
coefficient std. error z p-value
----------------------------------------------------------
const 538230 465497 1.156 0.2476
phi_1 0.131490 0.100374 1.310 0.1902
phi_2 0.191134 0.100067 1.910 0.0561 *
Mean dependent var 537205.3 S.D. dependent var 3202841
Mean of innovations -1303.320 S.D. of innovations 3081674
R-squared 0.976114 Adjusted R-squared 0.975854
Log-likelihood -1537.883 Akaike criterion 3083.767
Schwarz criterion 3093.940 Hannan-Quinn 3087.876
Real Imaginary Modulus Frequency
-----------------------------------------------------------
AR
Root 1 1.9691 0.0000 1.9691 0.0000
Root 2 -2.6570 0.0000 2.6570 0.5000
-----------------------------------------------------------
Residuos y su correlograma
res1 = $uhat
gnuplot res1 --time-series --with-lines --output="res1.png"
corrgm res1 10 --plot="res1_ACF-PACF.png"
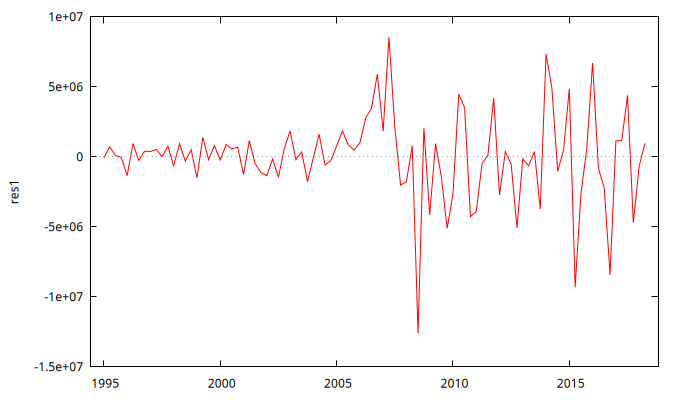
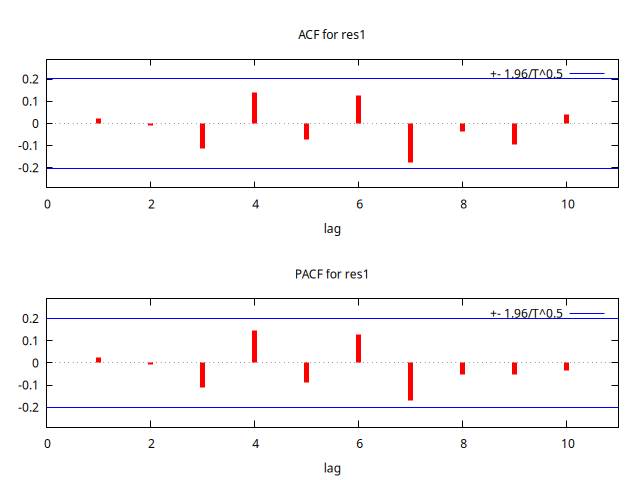
Estadístico Ljung-Box para los residuos
Autocorrelation function for res1
***, **, * indicate significance at the 1%, 5%, 10% levels
using standard error 1/T^0.5
LAG ACF PACF Q-stat. [p-value]
1 0.0230 0.0230 0.0515 [0.820]
2 -0.0078 -0.0084 0.0576 [0.972]
3 -0.1115 -0.1112 1.2913 [0.731]
4 0.1373 0.1442 3.1828 [0.528]
5 -0.0732 -0.0861 3.7261 [0.589]
6 0.1264 0.1277 5.3642 [0.498]
7 -0.1745 * -0.1674 8.5221 [0.289]
8 -0.0375 -0.0508 8.6700 [0.371]
9 -0.0938 -0.0535 9.6033 [0.384]
10 0.0381 -0.0321 9.7589 [0.462]
Segundo modelo univariante tentativo
arima 0 1 2 ; BE_2_5_8_16
Function evaluations: 20
Evaluations of gradient: 8
Model 4: ARIMA, using observations 1995:1-2018:2 (T = 94)
Estimated using AS 197 (exact ML)
Dependent variable: (1-L) BE_2_5_8_16
Standard errors based on Hessian
coefficient std. error z p-value
-----------------------------------------------------------
const 541065 430005 1.258 0.2083
theta_1 0.166904 0.104493 1.597 0.1102
theta_2 0.191221 0.0921310 2.076 0.0379 **
Mean dependent var 537205.3 S.D. dependent var 3202841
Mean of innovations -202.4457 S.D. of innovations 3082802
R-squared 0.976050 Adjusted R-squared 0.975789
Log-likelihood -1537.914 Akaike criterion 3083.829
Schwarz criterion 3094.002 Hannan-Quinn 3087.938
Real Imaginary Modulus Frequency
-----------------------------------------------------------
MA
Root 1 -0.4364 -2.2448 2.2868 -0.2806
Root 2 -0.4364 2.2448 2.2868 0.2806
-----------------------------------------------------------
Residuos y su correlograma
res2 = $uhat
gnuplot res2 --time-series --with-lines --output="res2.png"
corrgm res1 10 --plot="res2_ACF-PACF.png"
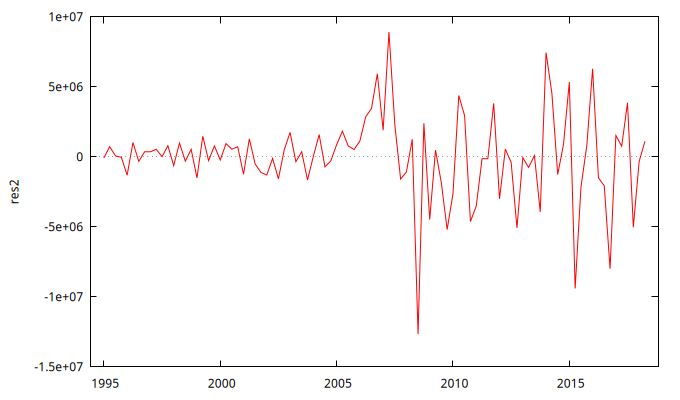
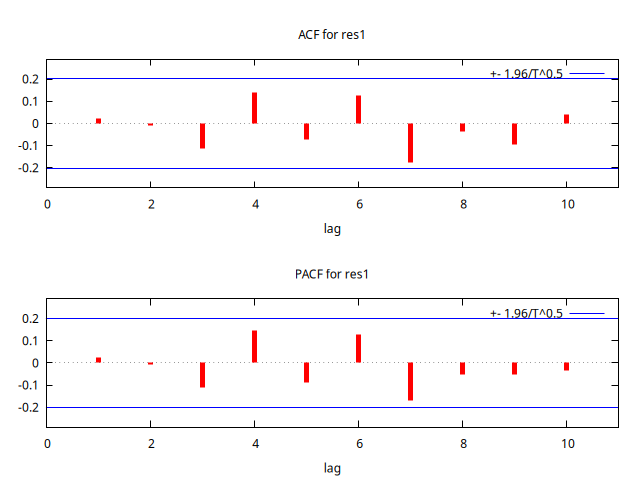
Estadístico Ljung-Box para los residuos
Autocorrelation function for res2
***, **, * indicate significance at the 1%, 5%, 10% levels
using standard error 1/T^0.5
LAG ACF PACF Q-stat. [p-value]
1 -0.0117 -0.0117 0.0132 [0.908]
2 0.0214 0.0213 0.0582 [0.971]
3 -0.0629 -0.0624 0.4502 [0.930]
4 0.1700 0.1689 3.3469 [0.502]
5 -0.0926 -0.0914 4.2173 [0.519]
6 0.1322 0.1286 6.0104 [0.422]
7 -0.1788 * -0.1702 * 9.3248 [0.230]
8 -0.0301 -0.0631 9.4199 [0.308]
9 -0.0965 -0.0564 10.4087 [0.318]
10 0.0357 -0.0300 10.5457 [0.394]
Preguntas
Pregunta 1
Discuta de todas las formas posibles si la serie temporal (BE_2_5_8_16) es estacionaria en media (i.e., si podemos asumir que es una realización de un proceso estocástico estacionario en media),
usando para ello los resultados del apartado Cuentas Financieras. Metodología SEC2010. Saldo. Otros activos/pasivos. Todos los sectores. Resto del mundo, Miles de Euros así como sus subapartados.
Pregunta 2
Discuta de todas las formas posibles si la primera diferencia de serie temporal (BE_2_5_8_16) es estacionaria en media usando para ello los resultados de los subapartados de la sección Datos en primeras diferencias.
Pregunta 3
Destaque los principales resultados de cada uno de los dos modelos univariantes.
Pregunta 4
Compare los dos modelos univariantes. ¿Cuál considera que es mejor? ¿por qué?
Pregunta 5
¿Que modificaciones sugiere para el modelo que haya escogido en el apartado anterior?
Pregunta 6
- Escriba el primer modelo univariante en forma de ecuación ARIMA.
- Escriba el segundo modelo univariante en forma de ecuación ARIMA.
Respuestas
Respuesta 1
La serie BE_2_5_8_16 parece ser NO estacionarias en media:
- En el gráfico se observa una persistente evolución creciente hasta el año 2008 y decreciente tras 2008
- La función de autocorrelación (FAC) muestra persistencia (sus coeficientes decrecen despacio y a un ritmo aproximadamente lineal). Además el primer coeficiente tiene un valor próximo a uno.
- El contraste Dickey-Fuller aumentado no rechaza la hipótesis nula de existencia de una raíz unitaria a niveles de significación inferiores al 80%.
- En consonancia con lo anterior, el test KPSS rechaza que la serie sea estacionaria tanto al 10% como al 5% y al 1%.
Aclaraciones a algunas respuestas incorrectas en los exámenes:
La identificación de un modelo ARIMA se hace analizando el correlograma de datos de los que podamos asumir que son realización de un proceso estacionario (y el primer apartado precisamente induce a rechazar que
BE_2_5_8_16sea ``estacionaria'').Por tanto, identificar un modelo a partir de los datos
BE_2_5_8_16en niveles es completamente incorrecto (pues no son estacionarios y previamente hay que diferenciarlos). Consecuentemente, aunque el primer retardo de la PACF es el único significativo (dado que la ACF no decae exponencialmente) no podemos identificar que el modelo sea un AR(1). Si quiere comprobarlo, estime un modelo AR(1) con los datos en niveles, verá que los residuos no son (ni remotamente) la realización de un proceso de ruido blanco; es decir, el modelo no es un AR(1).- Al realizar el contraste KPSS se rechaza (o quizá NO) la hipótesis nula del contraste KPSS; es decir, la hipótesis \(H_0\): el proceso es I(0). Por tanto, es incorrecto afirmar que al realizar el contraste KPSS se rechaza la hipótesis nula del contraste ADF, puesto que la \(H_0\) de este último contraste es que el proceso es I(1) (¡que es una hipótesis distinta!).
- Decir que ``se rechaza el contraste ADF'' (o cualquier otro contraste) es incorrecto. Lo que se rechaza es la hipótesis nula del contraste (pero nunca el contraste). Por poner otra analogía absurda\(\ldots{}\) se mastica la comida que hay en el plato (pero no se mastica ``el plato'').
En el correlograma, el primer palote (tanto de la ACF como la PACF) representa la magnitud de la autocorrelación de orden 1 (por tanto, el ``palote'' NO ES UN AR(1)\(\ldots{}\) recuerde que un AR(1) es un modelo y el palote representa el valor de un parámetro). Afirmar que un AR (es decir un modelo autorregresivo) es muy próximo a uno no tiene ningún sentido.
El primer primer ``palote'' de la ACF (y también de la PACF) es la correlación de orden uno. Usted debe saber que la correlación es un estadístico acotado entre -1 y 1, por tanto: JAMAS ningún coeficiente de la PACF (o la ACF) será mayor que uno (o menor que \(-1\)).
Respuesta 2
La serie d_BE_2_5_8_16 (la primera diferencia regular de BE_2_5_8_16) parece ``estacionaria'' en media:
- Analizando el gráfico podemos observar que oscila de manera regular alrededor de su media (aunque muestra un altibajo en su nivel en los años 2007 y 2008, por lo que es importante analizar otros posibles indicios que refuercen nuestra conclusión).
- La función de autocorrelación (FAC) decae rápidamente (tan solo son significativos los dos primeros retardos). El primer coeficiente tiene un valor muy inferior a uno.
- El contraste Dickey-Fuller aumentado rechaza contundentemente la hipótesis nula de existencia de una raíz unitaria (
valor p asintótico 1.259e-06). - En consonancia con lo anterior, el test KPSS NO rechaza que la serie sea estacionaria ni siquiera al 10% (por tanto tampoco al 5% o al 1%).
Aclaraciones a algunas respuestas incorrectas en los exámenes:
- No se rechazan los test de hipótesis, se rechazan las hipótesis nulas de los contrastes (véase de nuevo las aclaraciones generales al final del ejercicio LetrasTesoroAmericano3y6meses). Y es fundamental indicar qué dice cada hipótesis en cada caso; decir que se rechaza la hipótesis del contraste es no decir nada (véase de nuevo las aclaraciones generales al final del ejercicio LetrasTesoroAmericano3y6meses).
- El concepto de ``tendencia'' hace referencia a una descripción (subjetiva) de la evolución a medio o largo plazo del nivel de la serie. En el caso de una serie ``estacionaria'', es mejor decir: ``en esta serie se aprecia un nivel aproximadamente constante'', en lugar de ``una tendencia aproximadamente constante'' (pues tendencia hace referencia a la evolución del nivel; y en una serie estacionaria se espera que el nivel se mantenga estable, por eso, tendencia constante es una expresión poco inadecuada).
Respuesta 3
- Primer modelo.
- Es un AR(2) para la primera diferencia ordinaria de la serie (\(\nabla \mathbf{y}\)); es decir, es un modelo ARIMA(2,1,0).
Las raíces del polinomio AR están claramente fuera del círculo unidad (indicando que este modelo para la primera diferencia de los datos es estacionario).
Es más, mirando la ACF y la PACF se aprecia que los residuos parecen ser una realización de un proceso de ruido blanco, pues ningún retardo es estadísticamente significativo y, sobre todo, los p-valores de los estadísticos de Ljung-Box de los residuos son muy elevados, por lo que no se puede rechazar la hipótesis nula de que los residuos sean ``ruido blanco''.
Por otra parte, NI la constante NI el parámetro correspondiente al primer retardo del modelo AR son estadísticamente significativos. Aunque el modelo arroja un \(R^2\) muy elevado (
0,97611); esto no indica nada en absoluto, es lo que cabe esperar cuando se ajusta un modelo a series con tendencia (aunque el modelo sea muy malo, lo habitual es que el cálculo del \(R^2\) arroje un valor muy elevado). - Segundo modelo.
- Es un MA(2) para la primera diferencia ordinaria de la serie (\(\nabla \mathbf{y}\)); es decir, es un modelo ARIMA(0,1,2).
Las raíces del polinomio MA están claramente fuera del círculo unidad (indicando que este modelo para la primera diferencia de los datos es invertible).
Es más, al igual que en el modelo anterior (y por los mismos motivos) no se puede rechazar la hipótesis de que los residuos sean ``ruido blanco''.
Por otra parte, NI la constante, NI el parámetro correspondiente al primer retardo del modelo MA son estadísticamente significativos. Dado que la serie es no estacionaria en media, el valor del \(R^2\) es muy elevado (
0,97605) (pero como se ha dicho más arriba, este valor no es interpretable, es lo que cabe esperar en los ajustes de series no estacionarias en media).
Aclaraciones a algunas respuestas incorrectas en los exámenes:
- Lo primero y fundamental es indicar el tipo de modelo: si el modelo es AR, MA o ARMA. Para ello es imprescindible indicar si es un modelo de los datos en niveles o si lo es de los datos en diferencias.
El cálculo del coeficiente de determinación es \(R^2=1 -\frac{\sum\widehat{e_t}^2}{\sum (y_t-\bar{y})^2}\). Dado que la serie no es estacionaria en media (dado que la serie deambula), la mayoría de sus valores resultan estar lejos de la media muestral. En consecuencia, el denominador resulta ser muchísimo más grande que la suma del cuadrado de los errores de ajuste que aparece en el numerador (la serie ajustada suele estar próxima a los datos, deambulando con ellos al tratar de seguir la trayectoria de la serie temporal en el ajuste). Por tanto la fracción \(\frac{\sum\widehat{e_t}^2}{\sum (y_t-\bar{y})^2}\) tendrá un valor muy pequeño y consecuentemente el \(R^2\) estará próximo a \(1\).
Por tanto que el \(R^2\) esté próximo a 1 no significa que el modelo sea muy ``explicativo''. Un modelo puede tener un \(R^2\) muy elevado y simultáneamente ser completamente inútil para explicar nada (hemos visto algunos ejemplos durante el curso\(\ldots{}\) repase el tema sobre la correlación espuria).
En el contexto de los modelos de regresión es habitual escuchar la coloquial expresión de que ``un modelo explica el \(X\) por ciento'' pero la frase no puede acabar ahí. Es necesario completarla diciendo ``el \(X\) por ciento de la varianza de los datos''.
Pero es que en el caso de los modelos ARMA (o ARIMA), que no son modelos de regresión con constante ajustados por MCO, la lectura del \(R^2\) ya no es un ratio entre la varianza muestral de los datos y la varianza de los datos ajustados. Tampoco es el cuadrado de la correlación muestral entre la serie y los datos ajustados.
Pero incluso en el contexto del ajuste MCO (que usted estudió en el primer curso de econometría) un \(R^2\) elevado, por sí solo, no ``explica'' nada. El \(R^2\) en modelos de regresión con constante tan solo es un ratio de varianzas muestrales (la del regresando \(y_t\) y la del ajuste \(\widehat{y_t}\)). Pero solo cabe pretender dar una interpretación a ese ratio si podemos considerar que modelo es una descripción ``teóricamente aceptable'' de la variable estudiada. Es decir, el verbo ``explica'' es un sinónimo —mal escogido— de ``replica (o reproduce) un \(X\) por ciento de la varianza de los datos''.
- Cuando se habla de si las raíces están fuera del círculo unidad, hay que especificar si las raíces son de un polinomio AR o MA, pues la lectura es distinta en cada caso (``modelo estacionario'' en el primer caso o ``modelo invertible'' en el segundo).
- En un modelo univariante no cabe hablar de correlaciones espurias (eso corresponde a correlaciones entre dos series distintas)
- Todo modelo AR es invertible (pues invertible significa que tiene representación AR); consecuentemente decir AR ``invertible'' es como decir: tengo un gato ``felino'' (¿hay alguno que no lo sea?).
- Todo modelo MA es estacionario; consecuentemente decir MA ``estacionario'' es como lo del ``gato felino''.
- El primer modelo univariante es un AR(2) y el segundo un MA(2). Estos modelos son MUY DISTINTOS entre si. Afirmar que son parecidos no está justificado de ningún modo.
- Un retardo significativo en la ACF o la PACF no es ``un atípico''. Aunque algunos datos pueden ser calificados de atípicos, los retardos de un correlograma NO.
- La alusión a los criterios de información no debe hacerse aquí. Debe hacerse en la Pregunta 4, que es donde se pide comparar los dos modelos de la misma variable
d_BE_2_5_8_16Afirmar (y transcribo literalmente): ``El módulo del AR resulta ser mayor que uno'' NO TIENE SENTIDO. En todo caso sería el módulo de la raíz del polinomio AR. Pero en este caso hay dos raíces, por lo que la frase tiene aún menos sentido. Lo que se puede decir del primer modelo es que las dos raíces del polinomio autorregresivo tienen módulos mayores que uno (o que ambas raíces autorregresivas están fuera del círculo unidad).
Peor aún (y vuelvo a transcribir): ``MA contiene un modulo mayor que uno'' (la negrita es mía pero la frase es del mismo examen).
En algún otro examen he leído: el modelo univariante no presenta MA y solo AR… otra frase más de esas sin ningún sentido…
En un examen escrito se debe cuidar especialmente el lenguaje, para lograr construir expresiones con pleno significado. Para ello se debe escoger correctamente el vocabulario; y esto solo es posible tras una adecuada comprensión de los conceptos.
Respuesta 4
Respecto a la identificación de los modelos: el correlograma de la serie en diferencias muestra un decaimiento más lento en la ACF que en la PACF; de hecho, la PACF muestra un abrupto decaimiento en el tercer retardo. Esto sugiere que el modelo es un AR(2).
La desviación típica de las innovaciones del primer modelo es menor. Además, los criterios de información son ligeramente inferiores en el primer modelo. Todos estos estadísticos apuntan a una ligera ventaja del primer modelo frente al segundo. Es más, los estadísticos de Ljung-Box para los residuos del primer modelo muestran unos p-valores sistemáticamente superiores a los del segundo.
Todo lo anterior, indica que el primer modelo parece ser más adecuado que el segundo.
Aclaraciones a algunas respuestas incorrectas en los exámenes:
- El p-valor es una probabilidad: la probabilidad (bajo la \(H_0\)) de que una variable aleatoria con la misma distribución del estadístico del contraste, tome un valor ``más extremo'' que el observado en la muestra (con más extremo queremos decir, más alejado del valor de la hipótesis nula).
- Consecuentemente, hablar del p-valor de los residuos no tiene sentido. Lo que si tiene sentido es referirse a los p-valores de los estadísticos del contraste Ljung-Box realizado sobre los residuos.
Respuesta 5
Ambos modelos tienen parámetros no significativos. Por tanto cabe la posibilidad de que el modelo mejore si se restringe la estimación para que tanto la constante como el parámetro correspondiente al primer retardo (en los respectivos modelos) sean cero. Es decir, cabe la posibilidad de que el modelo mejore si se eliminan los parámetros no significativos del modelo.
Aclaraciones a algunas respuestas incorrectas en los exámenes:
- Un modelo en el que \(\phi_1=0\) pero \(\phi_2\ne0\) sigue siendo un modelo AR(2); del mismo modo \(1-x+x^2\) es un polinomio de grado 2, pero también lo es \(1+x^2\) o incluso \(7x^2\). El orden del modelo AR lo da el mayor retardo significativo (y no el número de parámetros significativos).
- Lo mismo se puede decir de los modelos MA.
Respuesta 6
Redondeando:
- El primer modelo es:
\(\quad(1-0,131\ \mathsf{B}-0,191\ \mathsf{B}^2)(\nabla Y_t-538230) = U_t\)
o
\(\quad(1-0,131\ \mathsf{B}-0,191\ \mathsf{B}^2)\nabla Y_t = 538230(1-0,131\ \mathsf{B}-0,191\ \mathsf{B}^2) +U_t\)
o
\(\quad\nabla Y_t = 538230 + \frac{U_t}{1-0,192\ \mathsf{B}-0,326\ \mathsf{B}^2}\)
- El segundo modelo es:
\(\quad \nabla Y_t-541065 = (1+0,167\ \mathsf{B}+0,191\ \mathsf{B}^2) U_t\)
o
\(\quad\nabla Y_t = 541065 + (1+0,167\ \mathsf{B}+0,191\ \mathsf{B}^2) U_t\)
o
\(\quad \frac{\nabla Y_t-541065}{1+0,167\ \mathsf{B}+0,191\ \mathsf{B}^2} = U_t\)