Lección 9. Cointegración¶
Author: Marcos Bujosa
Correlación¶
La correlación entre dos muestras de tamaño $N$ (dos vectores de datos de $\mathbb{R}^N$) es el coseno del ángulo formado los vectores de datos en desviaciones respecto a sus correspondientes medias. $$\rho_{\boldsymbol{x}\boldsymbol{y}}=\frac{\sigma_{\boldsymbol{x}\boldsymbol{y}}}{\sigma_{\boldsymbol{x}}\sigma_{\boldsymbol{y}}}$$
Por tanto la correlación es algún valor entre $-1$ y $1$.
- Si la correlación es $1$ entonces $\;\boldsymbol{y}-\boldsymbol{\bar{y}}\;$ es $\;a(\boldsymbol{x}-\boldsymbol{\bar{x}})\;$ para algún $a$ positivo
- Si la correlación es $-1$ entonces $\;\boldsymbol{y}-\boldsymbol{\bar{y}}\;$ es $\;a(\boldsymbol{x}-\boldsymbol{\bar{x}})\;$ para algún $a$ negativo
- Cuando la correlación es $0$ el vector $\;\boldsymbol{y}-\boldsymbol{\bar{y}}\;$ es perpendicular al vector $\;\boldsymbol{x}-\boldsymbol{\bar{x}}\;$
La causalidad y correlación¶
Cuando existe relación causal entre variables sus muestras suelen estar correladas.
- Número de horas diurnas correlaciona positivamente con las temperaturas medias diarias.
- La altitud (o latitud) de un lugar correlaciona negativamente con su temperatura media anual.
Pero correlaciones significativas no indican la existencia de relaciones causales.
- En una playa: consumo de helados y ataques de tiburón a los bañistas
Correlación espuria¶
La correlación entre variables sin relación causal se denomina correlación espuria.
- Que haya correlación espuria NO significa que realmente no hay correlación.
- Que haya correlación espuria significa que es erróneo interpretar que la correlación es producto de una relación causal.
Puede ser que una causa común induzca la correlación entre ambas variables
- consumo de helados y venta de bañadores
Puede ser que no exista causa alguna y aún así haya correlación
- Un ejemplo
- Otro
- Otro más
- Más ejemplos aquí
Las series con tendencia suelen tener elevadas correlaciones.¶
Ejemplo de correlación espuria: PNB vs incidencia de melanoma¶
Serie anual (1936–1972) del PNB anual de EEUU en miles de millones de dólares corrientes e incidencia de melanoma en la población masculina de Connecticut.
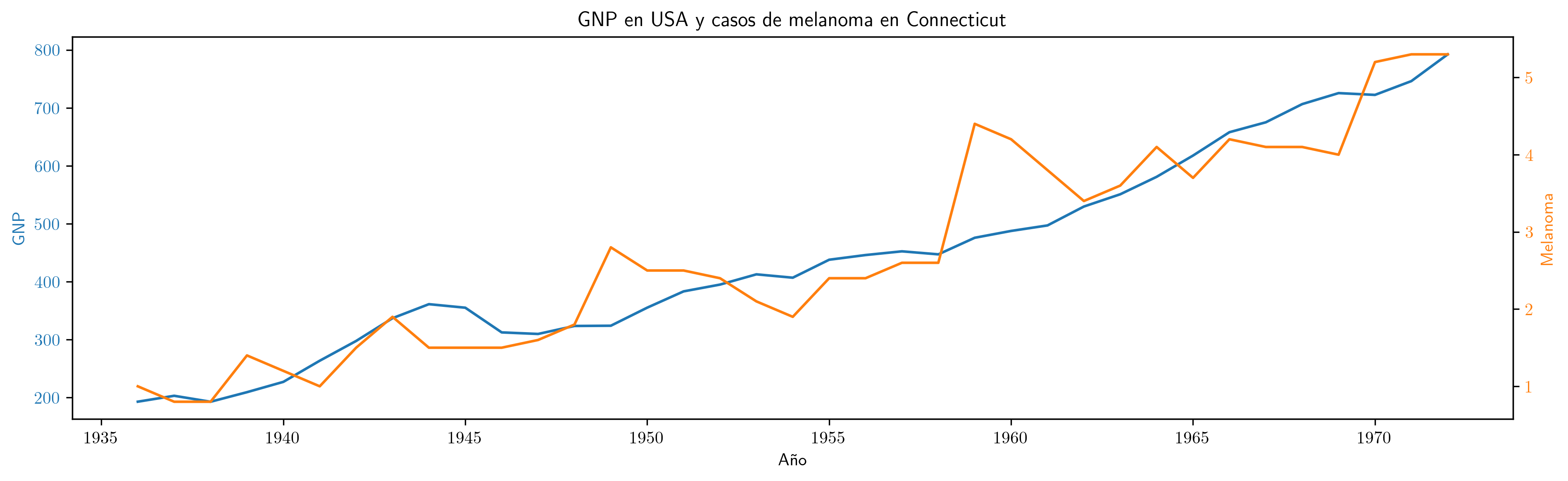
Como ambas series presentan una tendencia creciente, la correlación es muy elevada:
- Valor del coeficiente de correlación:
np.float64(0.932)
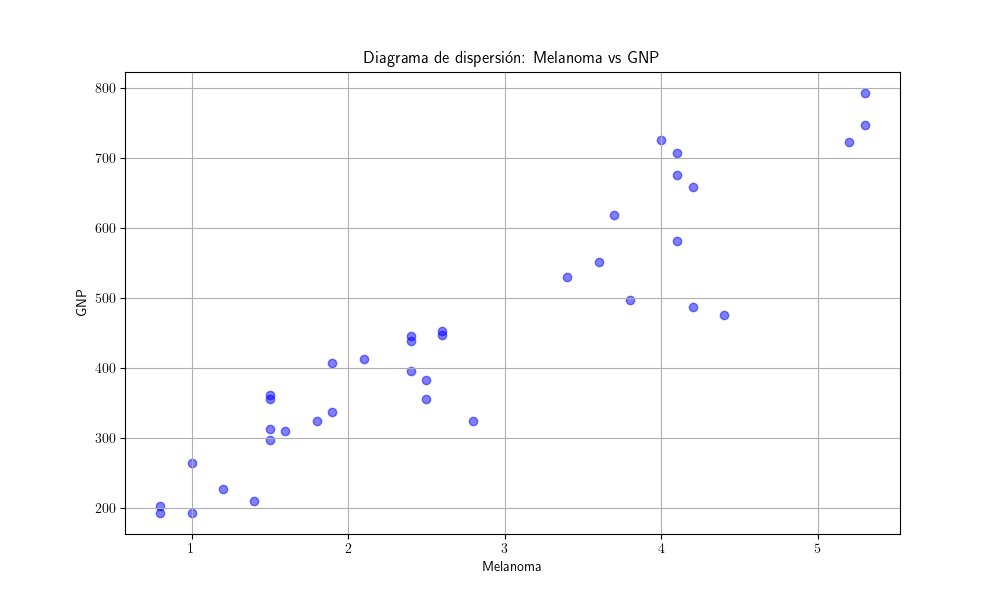
Regresión en niveles¶
La regresión del PNB sobre los casos de melanoma arroja un excelente ajuste (coef. de determinación muy elevdo) y los coeficientes son muy significativos tanto individual como conjuntamente.
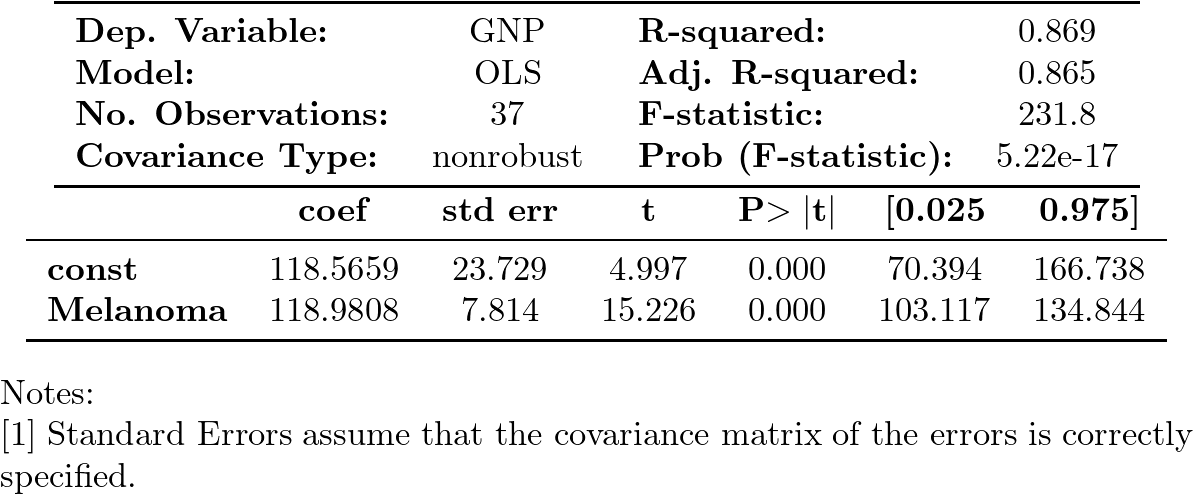
Pero esto no significa que el modelo sea bueno o tenga alguna capacidad explicativa o predictiva (los casos de melanoma en Connecticut no aumentan la producción de EEUU).
Explorando si la correlación es probablemente espuria (no causalidad)¶
Si fuera cierto que $$ \boldsymbol{y}=\beta_1 \boldsymbol{1} + \beta_2 \boldsymbol{x} + \boldsymbol{u}; $$ entonces también sería cierto que $$ \nabla\boldsymbol{y}= \beta_2 \nabla\boldsymbol{x} + \nabla\boldsymbol{u}. $$
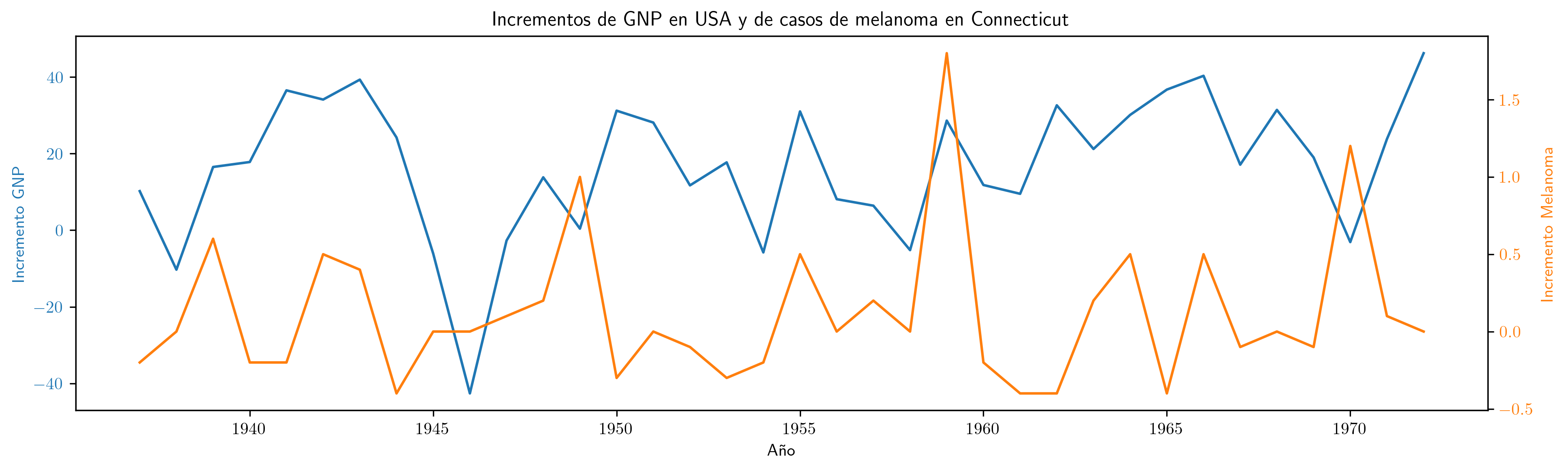
La aparente relación ya no se aprecia tras diferenciar las series.
Regresión en primeras diferencias¶
Además, al realizar la regresión de la primera diferencia de GNP sobre la primera diferencia de Melanoma,
obtenemos un ajuste pésimo (tan solo la constante es significativa… cuando debería ser la única no significativa).
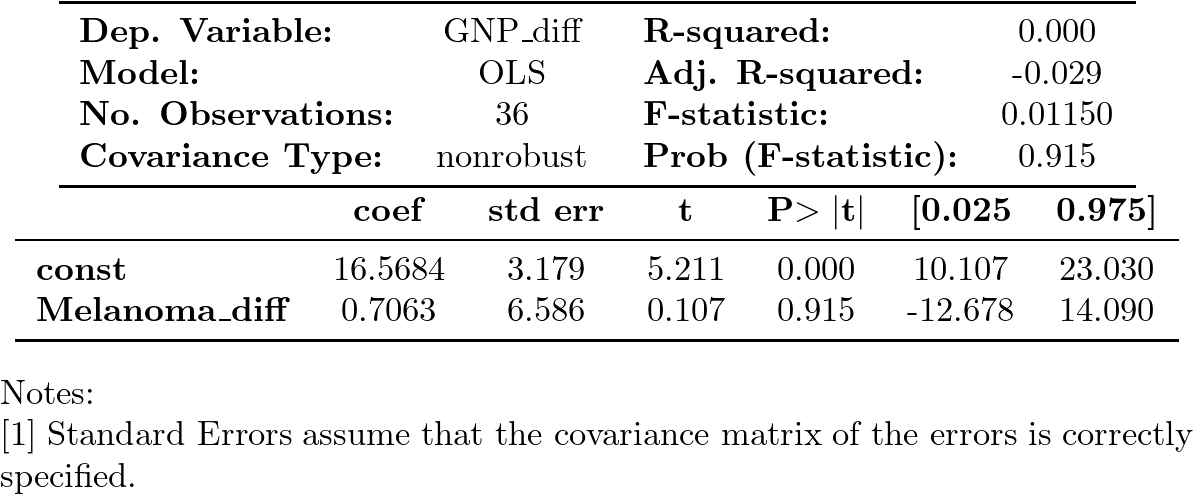
Todo confirma que la relación es (evidentemente) espuria
Cointegración¶
Un proceso estocástico $\boldsymbol{X}$ sin componentes deterministas es $I(0)$ si tiene representación ARMA estacionaria e invertible.
$\boldsymbol{X}$ es integrado de orden $d$ si $\;\nabla^d*\boldsymbol{X}\;$ es $I(0);\;$ entonces se dice que es $I(d)$.
En ocasiones una combinación lineal, de series con el mismo orden de integración $I(d)$, resulta ser integrada con un orden menor a $d$; entonces se dice que están cointegradas:
$\boldsymbol{x}$, $\boldsymbol{y}$ y $\boldsymbol{z}$ están cointegradas si son $I(d)$ y existen $a$, $b$, $c$ tales que $$a\boldsymbol{x}+b\boldsymbol{y}+c\boldsymbol{z}\quad\text{es cointegrada de orden $d-m$},$$ con $m>0\;$ (entonces se dice que hay $m$ relaciones de integración).
Para estimar la relación de cointegración, se ajusta una regresión lineal entre las variables potencialmente cointegradas y se evalúa el orden de integración de los residuos.
- La situación más habitual es tener dos series $\boldsymbol{x}$ e $\boldsymbol{y}$ que son $I(1)$ y encontrar por MCO un $\hat{\alpha}$ tal que $\boldsymbol{y}-\hat{\alpha}\boldsymbol{x}$ es $I(0)$.
La cointegración entre series temporales tiene dos interpretaciones relacionadas:
- Existe un equilibrio a largo plazo entre dichas series, de manera que las desviaciones del equilibrio tienden a desaparecer a corto plazo.
- Las series poseen una tendencia común (pues hay una combinación lineal entre ellas que cancela dicha tendencia).
Ejemplo de cointegración: tipos de interes en UK a corto y largo plazo¶
Long: rendimiento porcentual a 20 años de los bonos soberanos del Reino UnidoShort: rendimiento de las letras del tesoro a 91 días
(Muestra: 1952Q2–1970Q4)
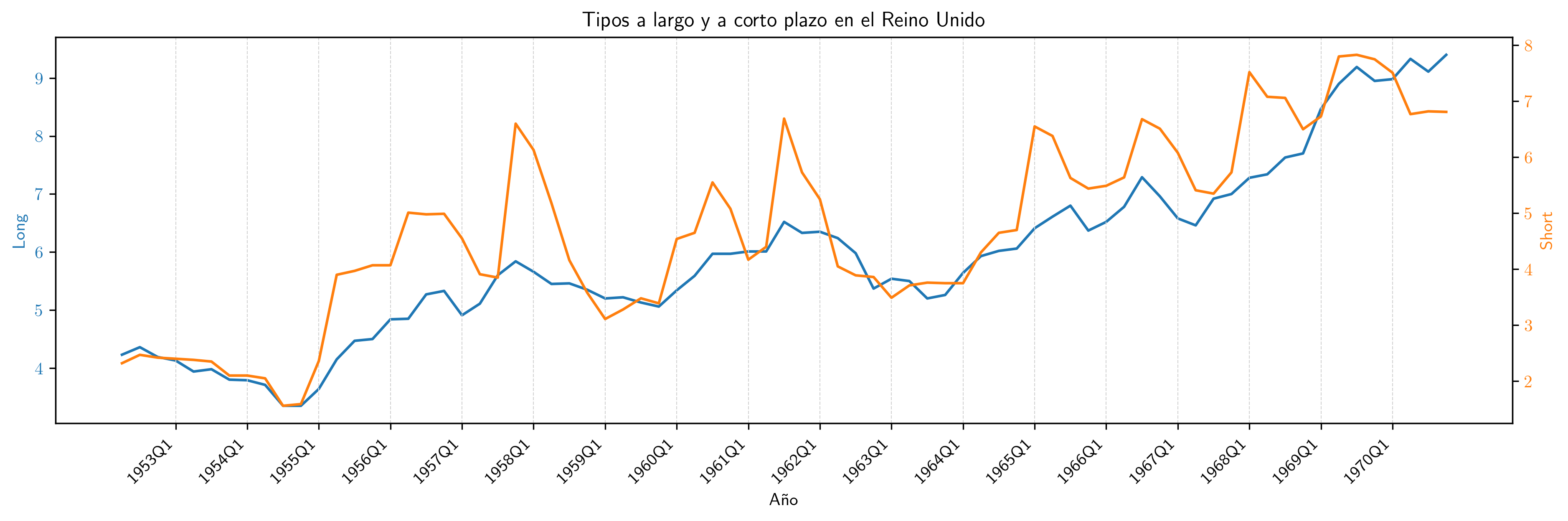
Como ambas series presentan una tendencia creciente, la correlación es muy elevada:
- Valor del coeficiente de correlación:
np.float64(0.898)
Series en diferencias¶
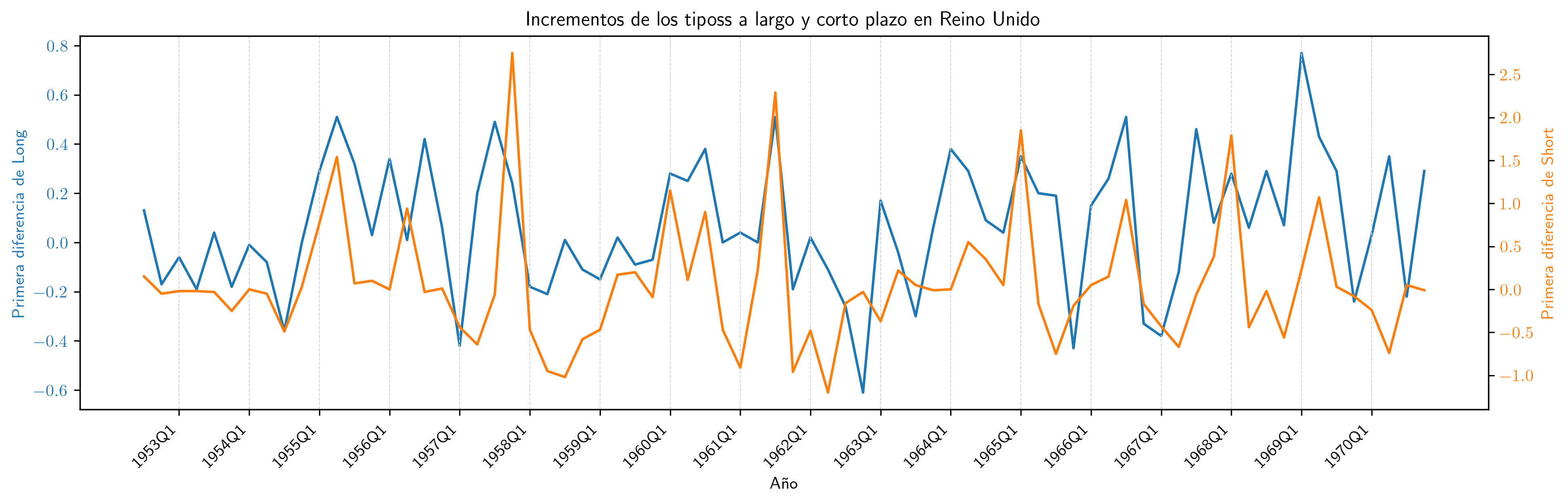
Resultados de la regresión en primeras diferencias de Short sobre Long
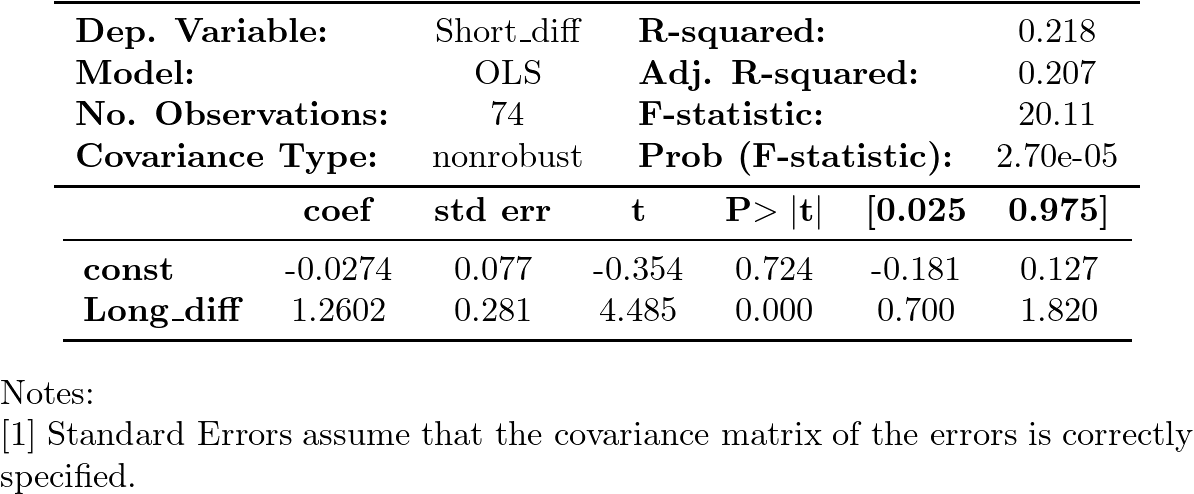
- el ajuste muestra un coeficiente de determinación razonable,
- con una pendiente muy significativa
- y una constante que no lo es.
Esta regresión NO sugiere que la correlación en niveles sea espuria
Regresión de las series en niveles¶
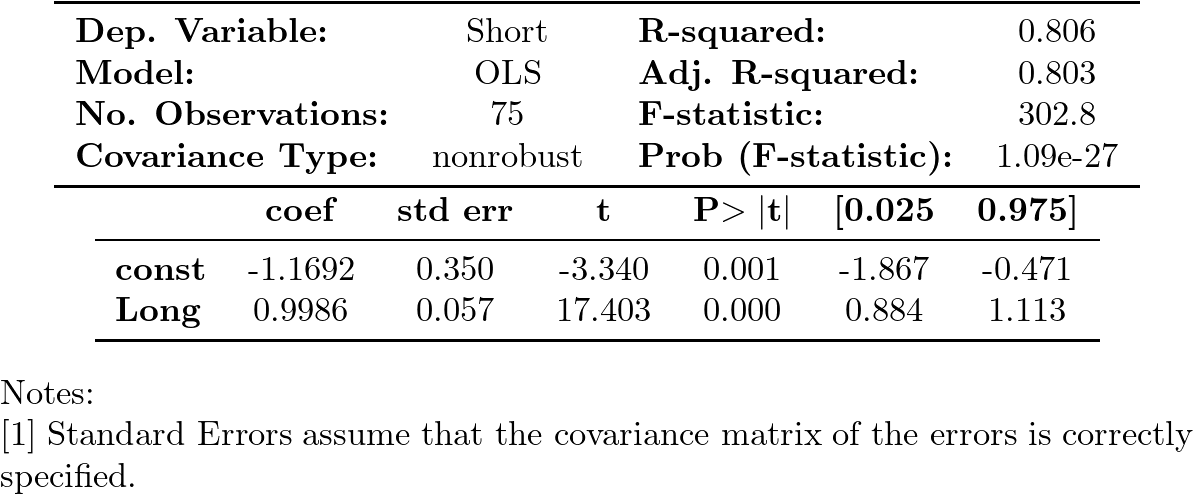
El $R^2$ es elevado y los parámetros son estadísticamente significativos.
La relación parece ser aproximadamente: $\;Long_t-Short_t=1.17+U_t$.
Si los residuos fueran ``estacionarios'' podríamos afirmar que los tipos a corto y a largo plazo están cointegrados.
Veamos si es así…
Análisis gráfico de los residuos¶
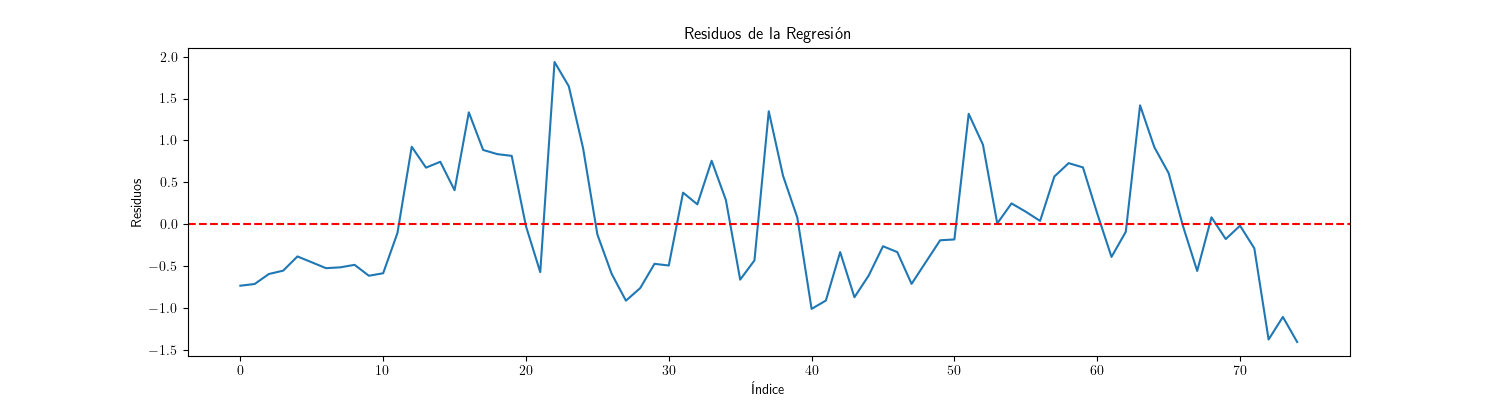
Por el gráfico, los residuos aparentan ser "estacionarios en media" (i.e., no se aprecia una tendencia evidente);
Contraste de hipótesis Dickey-Fuller de los residuos¶
from statsmodels.tsa.stattools import adfuller, kpss
# Contraste de Dickey-Fuller
adf_result = adfuller(residuos)
adf_stat, adf_p_value = adf_result[0], adf_result[1]
(adf_stat, adf_p_value)
(np.float64(-3.9628747023366064), np.float64(0.0016178852082981026))
Un p-valor tan bajo indica que debemos rechazar la hipótesis nula de que la serie es $I(1)$ con un nivel de significación del $\alpha=0.002$
Contraste de hipótesis KPSS de los residuos¶
# Contraste de KPSS
kpss_result = kpss(residuos, regression='c')
kpss_stat, kpss_p_value = kpss_result[0], kpss_result[1]
(kpss_stat, kpss_p_value)
/tmp/ipykernel_11594/3823668820.py:2: InterpolationWarning: The test statistic is outside of the range of p-values available in the look-up table. The actual p-value is greater than the p-value returned. kpss_result = kpss(residuos, regression='c')
(np.float64(0.09151679517238076), np.float64(0.1))
El test KPSS nos indica que el p-valor es mayor a $0.1$; por tanto no podemos rechazar la hipótesis nula de que la serie es $I(0)$ a los niveles de significación del 1, 5 o 10%.
Función de autocorrelación simple ACF de los residuos¶
Su aspecto es el de la ACF de una serie estacionaria.
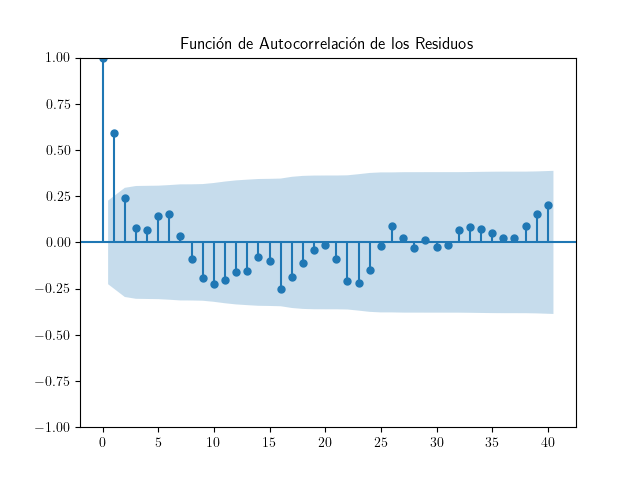
También podemos comprobar que el valor de la autocorrelación de orden 1 está lejos de la unidad.
# Calcular la autocorrelación de orden 1
np.corrcoef(residuos[:-1], residuos[1:])[0, 1]
np.float64(0.6120404093910319)
Su valor es claramente inferior a $1$.
Conclusión¶
Los análisis realizados sobre los residuos de la regresión entre los tipos de interés a corto y largo plazo sugieren que estos se comportan como un proceso estacionario.
- La gráfica no muestra una tendencia clara.
- El contraste de Dickey-Fuller mostró un p-valor de aproximadamente 0.0016, lo que permite rechazar la hipótesis nula de que la serie es no estacionaria.
- Por otro lado, el test KPSS resultó en un p-valor mayor a 0.1, indicándonos que no podemos rechazar la hipótesis nula de estacionariedad.
- Además, la función de autocorrelación de los residuos presenta un comportamiento típico de series estacionarias y una autocorrelación de orden 1 de aproximadamente 0.612, notablemente inferior a 1, lo que refuerza la conclusión de que los residuos no muestran una tendencia sistemática.
Los contrastes de raíz unitaria de las series que concluyen que son $I(1)$, más las regresiones efectuadas y la conclusión de que los residuos son $I(0)$, sugieren que los cambios en los tipos de interés a corto y largo plazo pueden estar cointegrados, lo que implica una relación estable entre ambas variables a lo largo del tiempo de tipo: $$Long_t-Short_t=Cte + U_t.$$